Suivi de la consommation par secteur économique
Attribuer les profils de charge aux activités économiques
Lors de la pénurie d’électricité de l’hiver 2022, l’Office fédéral de l’énergie (OFEN) a dû obtenir rapidement un aperçu de la situation en matière d’approvisionnement. C’est dans ce contexte que le tableau de bord énergétique a été créé pratiquement du jour au lendemain. La question s’est rapidement posée de savoir comment les différents groupes de consommateurs et les divers secteurs économiques se distinguaient en matière de consommation d’électricité. De telles informations sont essentielles pour mettre en œuvre, dans des situations d’approvisionnement extraordinaires, des mesures ciblées tout en minimalisant les impacts négatifs.
Le tableau de bord énergétique différencie actuellement trois catégories: les particuliers, les PME et les gros consommateurs. Cette classification offre un premier aperçu. Elle demeure à ce jour unique en Europe par son niveau de détail, mais atteint toutefois ses limites dès qu’il s’agit de formuler des constats par secteur économique ou même de définir les mesures à prendre. Pour une évaluation plus nuancée, il est nécessaire d’avoir recours à un regroupement (clustering) plus fin par activité économique, qui permet d’une part des analyses plus approfondies et, d’autre part, une planification et une mise en œuvre plus ciblées des mesures destinées à assurer la sécurité d’approvisionnement. Un tel clustering repose sur les profils de charge, c’est-à-dire les données issues des compteurs intelligents (smart meters). L’introduction de l’infrastructure de mesure numérique a été lancée dans le cadre de la Stratégie énergétique 2050, et son déploiement sera achevé en 2027.
Codes Noga
Pour une différenciation plus fine de la consommation d’électricité, les profils de charge fournis par les gestionnaires de réseau de distribution (GRD) doivent être associés à des informations sur l’entreprise. Les codes Noga, qui classent les entreprises en fonction de leur activité économique, jouent ici un rôle essentiel. La Noga signifie «Nomenclature générale des activités économiques» et désigne la systématique suisse de classification des branches économiques. Ces codes permettent d’agréger les données de consommation par branche économique, de les comparer de manière systématique et de les analyser dans le respect de la protection des données.
Une étude pilote menée avec l’OFEN [1] a examiné dans quelle mesure les profils de charge fournis par les GRD pouvaient être reliés aux données de base et classés par activité économique à l’aide des codes Noga. Pour ce faire, deux approches ont été envisagées: d’une part, l’attribution des codes Noga via des données de base telles que le numéro d’identification des entreprises (IDE) et, d’autre part, via une classification assistée par IA sur la base des profils de consommation.
Attribution via les données de base
Dans la première approche, les données de consommation de cinq GRD ont été reliées aux données des entreprises et classées à l’aide des codes Noga. Les profils de charge ont été reliés aux données de base via le numéro de point de mesure. L’approche était donc à la fois basée sur des règles et sur des données: l’attribution des points de mesure à des activités économiques n’a pas été réalisée à partir des profils de charge eux-mêmes, mais au moyen des métadonnées disponibles. Le code pouvait être déterminé directement à partir de l’IDE, pour autant qu’il soit disponible. Le registre des entreprises et des établissements (REE) tenu par l’Office fédéral de la statistique (OFS) permet en effet de récupérer, à partir de l’IDE, le code Noga correspondant [2].
Dans les cas où les informations étaient incomplètes (absence d’IDE), l’attribution a été réalisée à partir du nom de l’entreprise et de ses coordonnées. Les ensembles de données fournis variant fortement en termes de structure, d’exhaustivité et de degré de détail, un traitement préalable des données s’est avéré nécessaire. Celui-ci comprenait notamment l’harmonisation des données des entreprises ainsi que la correction des adresses erronées ou incomplètes.
Sur la base des données corrigées, l’IDE a ensuite été déterminé via le service web public «Registre IDE» de l’OFS [3]. Afin d’éviter les erreurs d’attribution, seuls les résultats présentant un haut degré de concordance ont été pris en compte. Pour chaque résultat de recherche, le registre des entreprises fournit une note qualitative, qui a servi de critère décisionnel.
Agrégation par divisions Noga
Pour les analyses suivantes, les codes Noga à six chiffres ont été réduits aux deux premiers chiffres (par exemple, 104100 a été réduit à 10) et agrégés ainsi au niveau desdites divisions Noga. Cette agrégation permet une évaluation fiable par secteur d’activité, même avec un volume de données limité, et garantit une comparabilité cohérente entre les différentes zones de réseau. Il s’agit d’un compromis équilibré entre niveau de détail, comparabilité et disponibilité des données.
Attribution d’un code Noga
Dans l’étape suivante, la consommation d’électricité, disponible sous forme de profils de charge avec une résolution de 15 minutes, a été attribuée aux divisions Noga identifiées. Le traitement des données a été automatisé dans un pipeline implémenté en Python. Pour l’analyse, les profils de charge ont été agrégés sur la période disponible de 2018 à 2024 et visualisés par secteur d’activité pour chaque GRD.
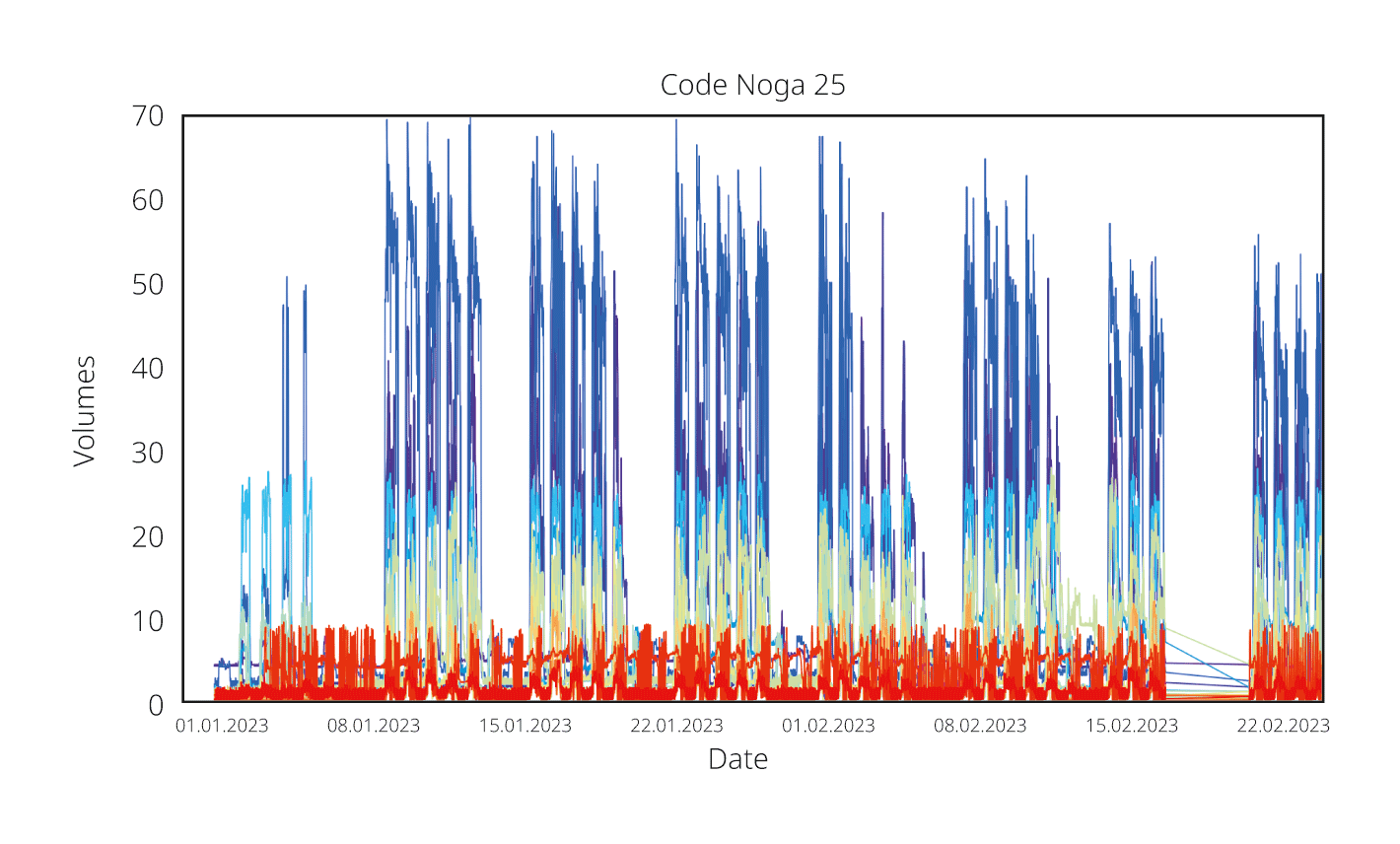
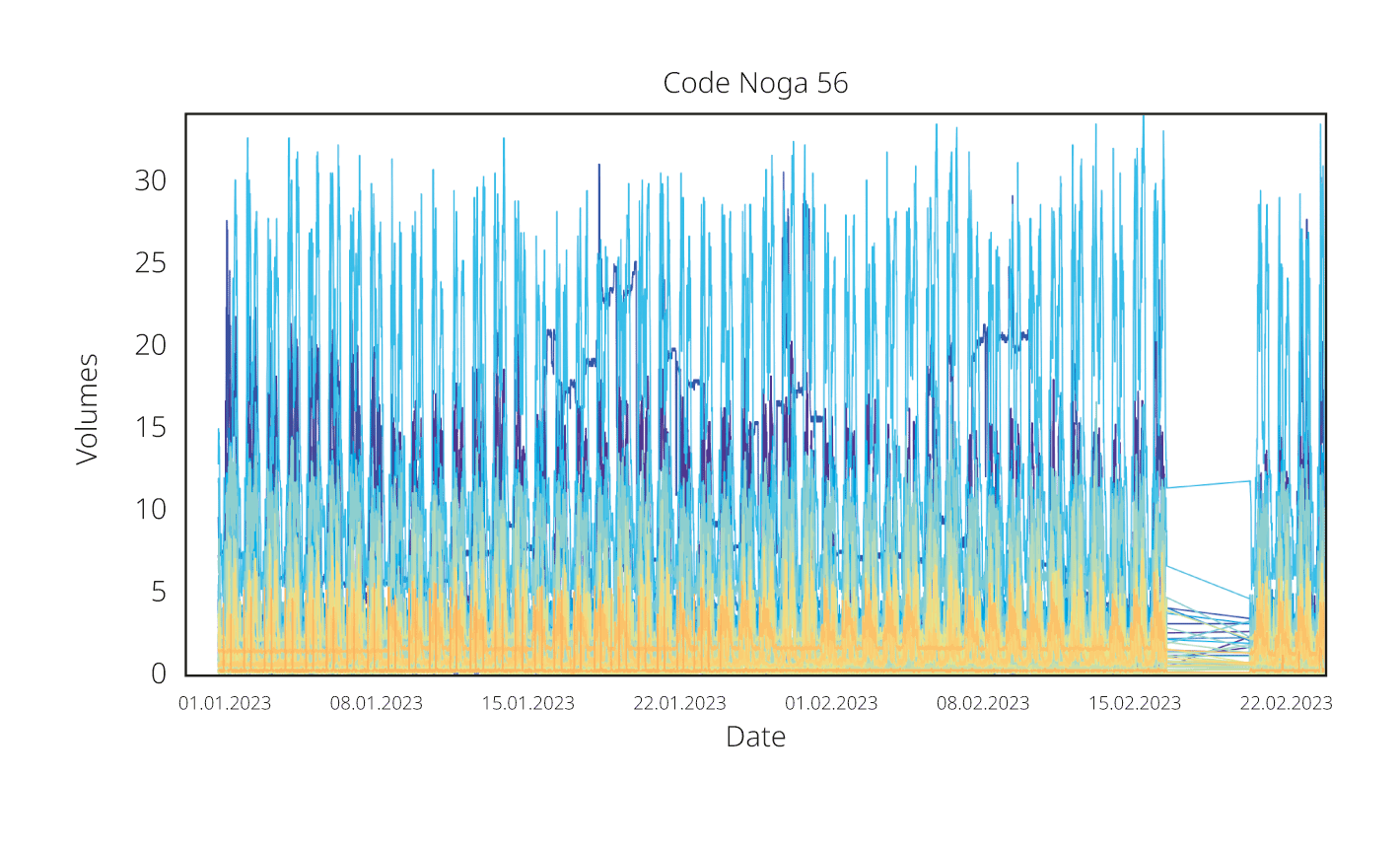
L’évaluation des points de mesure et de leur répartition entre les divisions Noga fournit des indications sur l’importance de la représentation des différents secteurs d’activité dans une zone de réseau ainsi que sur la pertinence d’une différenciation plus fine. Une part de 25% des points de mesure au sein d’un secteur économique a été définie comme seuil pragmatique pour une différenciation plus poussée de la division Noga. Si une division Noga dépassait cette part, elle était décomposée au niveau Noga inférieur suivant.
Consommateurs caractéristiques
La consommation d’électricité par secteur économique permet d’analyser les contributions relatives des différents secteurs économiques à la consommation totale d’électricité d’une zone de réseau. Les analyses ont montré que les secteurs économiques comptant de nombreux points de mesure ne présentent pas nécessairement les parts de consommation les plus élevées, et inversement.
La comparaison entre différents GRD montre en outre que la composition des secteurs économiques varie d’une région à l’autre. L’examen de la répartition de la consommation sur plusieurs années (de 2018 à 2024) montre que les parts relatives des secteurs économiques dans la consommation totale d’électricité d’un GRD restent globalement stables dans le temps.
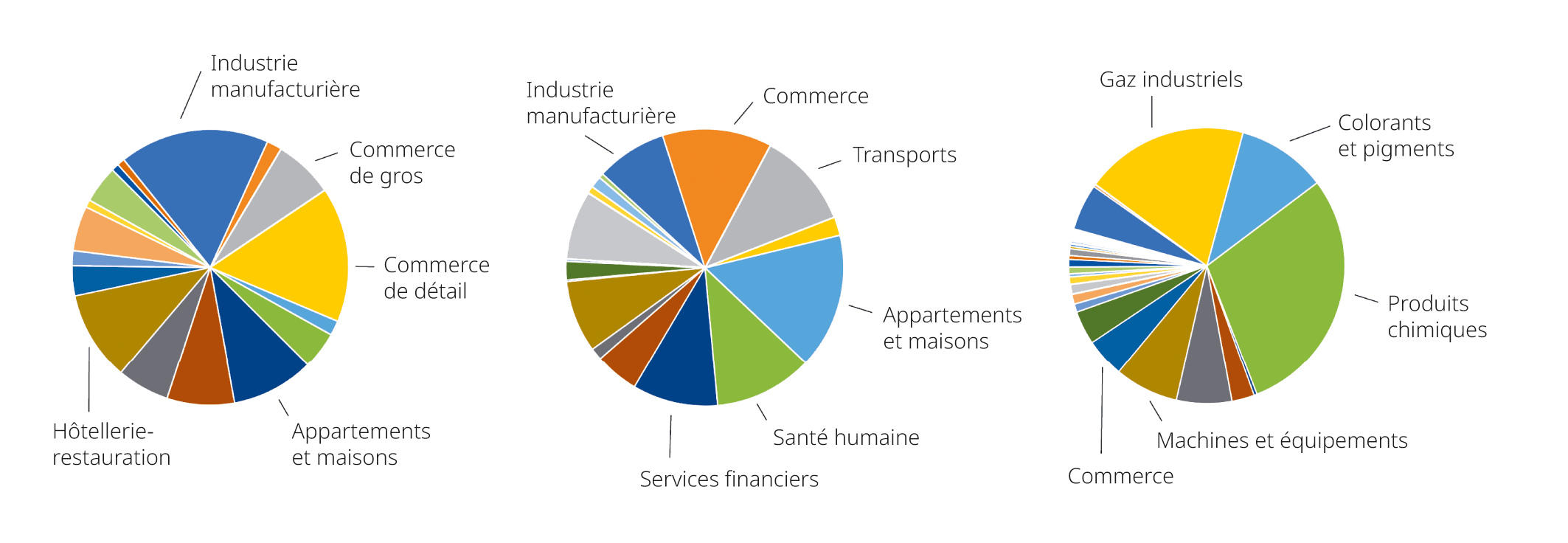
Dans l’ensemble, l’approche consistant à attribuer les divisions Noga à l’aide des données de base montre que, même avec une base de données limitée, une différenciation pertinente et largement automatisée par secteur économique est possible. Les résultats fournissent un aperçu fiable des structures de consommation caractéristiques et constituent une base appropriée pour des analyses plus approfondies. Tous les éléments de programme développés dans le cadre de cette approche sont disponibles en open source sous forme de référentiel sur le compte GitHub [4] de l’OFEN et peuvent être réutilisés par les GRD pour nettoyer leurs données de base.
Attribution à l’aide de l’IA
La deuxième approche a consisté à examiner si les profils de charge pouvaient être automatiquement attribués aux activités économiques à l’aide de méthodes d’apprentissage automatique (machine learning). Contrairement à la première approche, qui repose sur le couplage des données de consommation d’électricité (profils de charge) avec les données d’entreprise, l’accent est ici mis sur la classification directe des profils de charge selon les divisions Noga sans avoir recours à des données de base telles que l’IDE. L’objectif consistait à évaluer le potentiel des procédures basées sur les données pour une attribution automatisée par secteur d’activité et à mettre en évidence leurs limites.
Les profils de charge traités dans le cadre de la première approche et enrichis de codes Noga ont servi de base de données. Ceux-ci sont disponibles avec une résolution temporelle de 15 minutes et ont été transférés dans une structure de données uniforme pour les analyses ultérieures.
Limiter le nombre de divisions Noga
L’un des principaux défis de la classification assistée par IA réside dans le nombre élevé de divisions Noga possibles. Rien qu’au niveau des codes Noga à deux chiffres, il existe déjà 99 divisions, ce qui pose un problème de classification avec un très grand nombre de classes. À cela s’ajoute le fait que les points de mesure disponibles sont répartis de manière inégale entre les différentes divisions Noga. La base de données limitée et la représentation inégale des points de mesure rendent impossible une classification directe des profils de charge dans les 99 divisions. En conséquence, l’accent a été mis sur une sélection de divisions Noga disposant d’une base de données suffisante, complétée par la catégorie «Autres».
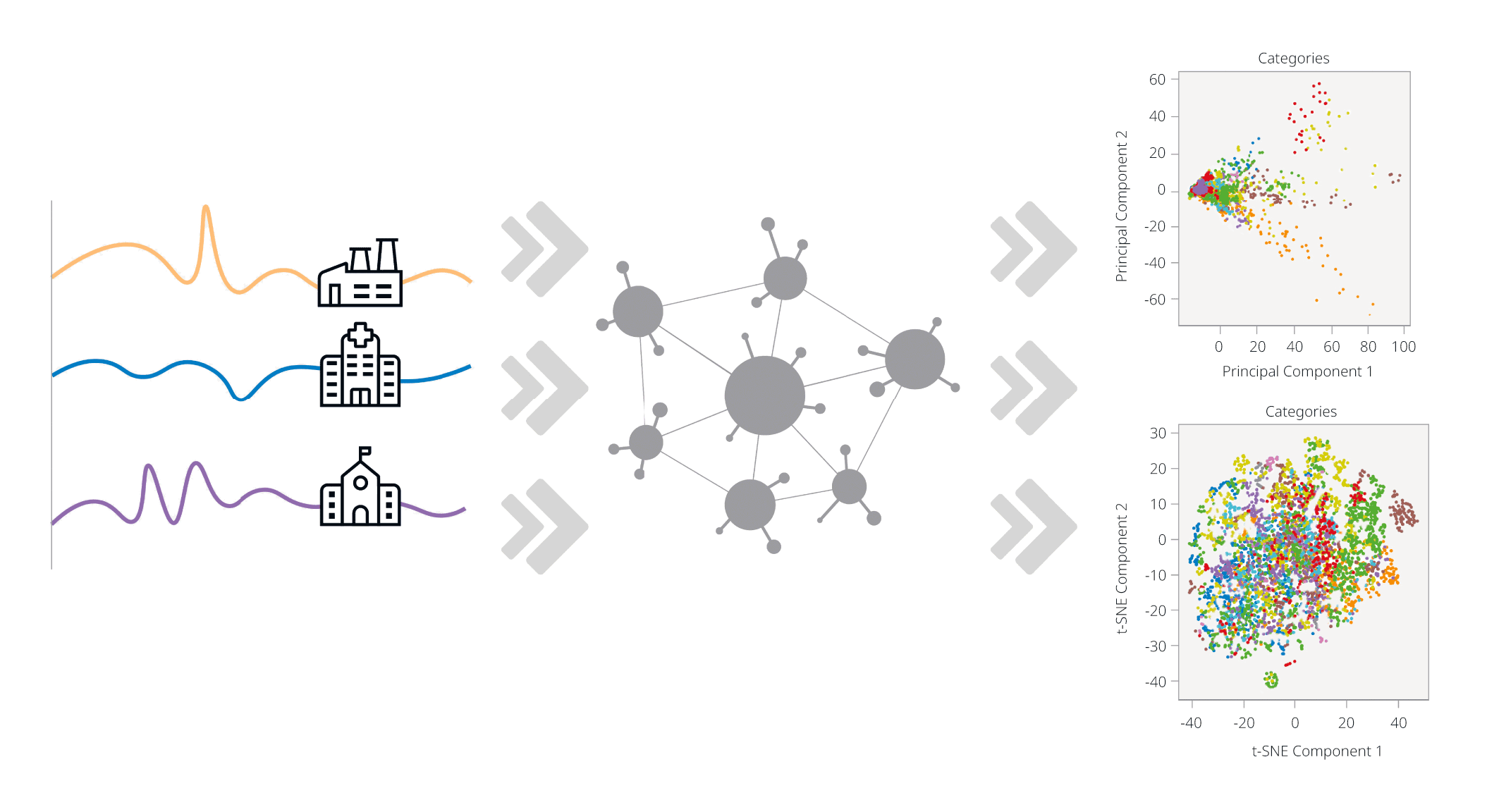
Avant le développement du modèle d’apprentissage automatique, des analyses exploratoires ont été menées afin d’étudier les différences et les similitudes des profils de charge des différents secteurs économiques. Pour ce faire, des méthodes telles que l’analyse en composantes principales (Principal Component Analysis, PCA) ont été utilisées. Cette dernière permet de mettre en évidence des structures cachées dans des données à haute dimension. Il apparaît que certaines divisions Noga présentent des modèles de consommation caractéristiques, tandis que d’autres sont difficiles à distinguer les unes des autres. Ces observations ont servi de base à la sélection des divisions étudiées ainsi qu’aux décisions méthodologiques qui ont suivi.
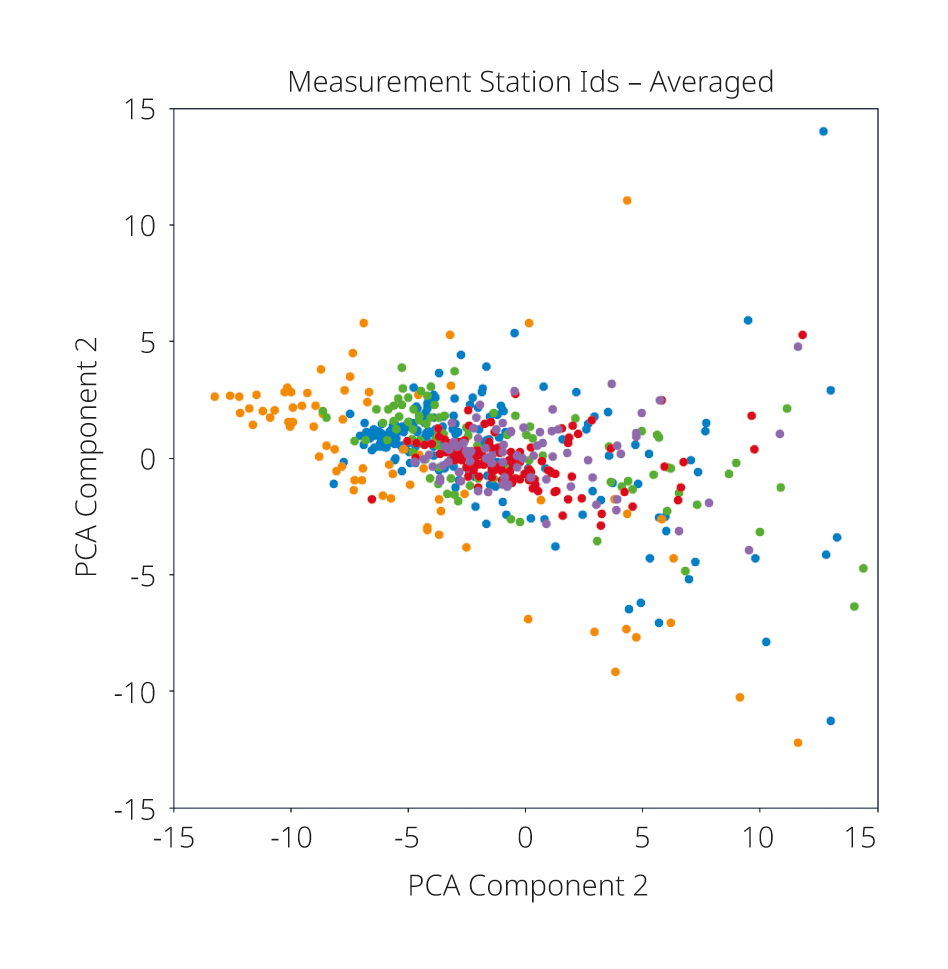
Définir les caractéristiques
Dans un deuxième temps, les sept divisions Noga comptant le plus grand nombre de points de mesure ont été sélectionnées, et l’étude a porté sur les caractéristiques permettant de distinguer leurs profils de charge. Ces caractéristiques, également appelées «features» dans la terminologie du machine learning, ont été analysées pour des séries temporelles de durées variables. Ont notamment été examinés des profils de charge journaliers avec une résolution temporelle d’un quart d’heure, des profils hebdomadaires agrégés ainsi que des séries temporelles s’étendant sur plusieurs semaines.
Dans les analyses, une série temporelle sur quatre semaines s’est avérée particulièrement appropriée, car elle reflète à la fois les modèles de consommation à court et à long terme. Les caractéristiques considérées comprenaient des indicateurs statistiques simples, tels que les valeurs minimales et maximales de la série temporelle, ainsi que des caractéristiques plus complexes, dérivées automatiquement des séries temporelles. La bibliothèque logicielle open source Tsfresh a été utilisée pour l’extraction automatisée des caractéristiques. Elle a notamment permis de calculer des moyennes, des variances ainsi que des caractéristiques basées sur la fréquence, telles que des transformations de Fourier (FFT) et des caractéristiques basées sur les ondelettes (formes d’onde).
Algorithmes open source
Aussi bien des modèles classiques d’apprentissage automatique que des réseaux neuronaux plus modernes ont été utilisés pour la classification des profils de charge. XGBoost (eXtreme Gradient Boosting) compte notamment parmi les approches classiques utilisées. Cette méthode est particulièrement adaptée aux données structurées et permet une modélisation efficace des relations non linéaires. Le modèle de gradient résout des problèmes d’optimisation en recherchant le minimum d’une fonction. Il suit le gradient de manière itérative.
En complément, des réseaux de type LSTM (Long Short-Term Memory) ont été utilisés. Les modèles LSTM font partie des réseaux neuronaux récurrents, c’est-à-dire à rétroaction, et sont spécialement conçus pour détecter les dépendances temporelles dans les données séquentielles. Ils sont donc bien adaptés à la reconnaissance de modèles dans les profils de charge.
L’utilisation de ces deux classes de modèles a permis de comparer les approches établies d’apprentissage automatique basées sur les caractéristiques et les réseaux neuronaux basés sur les séquences, qui réagissent directement à l’évolution temporelle des données de consommation.
Plus de données pour plus de précision
Au cours de l’analyse, il est rapidement apparu que la quantité de données disponible ne permettait de classifier au maximum que trois à quatre divisions Noga – et ce, uniquement pour les divisions disposant du plus grand nombre de points de mesure. La précision de la classification était, dans le meilleur des cas, d’environ 85% pour l’attribution à trois divisions Noga et de 80% pour l’attribution à quatre divisions.
Les résultats montrent clairement que pour une classification exhaustive des 99 divisions Noga, il faut disposer de données nettement plus nombreuses et plus variées. Pour pouvoir garantir un entraînement robuste et une application fiable des modèles de machine learning, une base de données de profils de charge plus ample et plus équilibrée est indispensable.
Les approches d’analyse et de modélisation utilisées dans le cadre de cette approche ont été mises en œuvre sous forme de code Python et de notebooks Jupyter. Le référentiel de code correspondant est disponible dans le compte GitHub [4] de l’OFEN.
Registre central des données de référence
Grâce à la plateforme nationale de données dans le secteur de l’électricité, une base de données nettement plus large sera disponible à l’avenir. Ceci permettra de poursuivre le développement des approches décrites. Néanmoins, attribuer de manière fiable les 99 divisions Noga uniquement à l’aide d’un modèle de classification reste un objectif ambitieux. La question de savoir si les modèles d’IA remplaceront l’attribution classique basée sur les métadonnées reste ouverte.
Un élément essentiel de la plateforme nationale de données est le registre des données de référence, qui doit également contenir les codes Noga des points de mesure. Cela facilitera l’accès à des profils de charge anonymisés, ce qui pourra favoriser davantage l’utilisation d’algorithmes intelligents pour l’analyse et la classification.
Les GRD qui n’ont pas encore procédé à une saisie systématique des divisions Noga peuvent utiliser les algorithmes élaborés et publiés de la première approche pour compléter leurs données de référence. Ils ont ainsi la possibilité d’évaluer la consommation d’électricité de leurs clients de manière agrégée par activité économique et d’obtenir des informations supplémentaires pour la planification et le suivi.
Suivi de la consommation par secteur économique
Attribuer les profils de charge aux activités économiques
Lors de la pénurie d’électricité de l’hiver 2022, l’Office fédéral de l’énergie (OFEN) a dû obtenir rapidement un aperçu de la situation en matière d’approvisionnement. C’est dans ce contexte que le tableau de bord énergétique a été créé pratiquement du jour au lendemain. La question s’est rapidement posée de savoir comment les différents groupes de consommateurs et les divers secteurs économiques se distinguaient en matière de consommation d’électricité. De telles informations sont essentielles pour mettre en œuvre, dans des situations d’approvisionnement extraordinaires, des mesures ciblées tout en minimalisant les impacts négatifs.
Le tableau de bord énergétique différencie actuellement trois catégories: les particuliers, les PME et les gros consommateurs. Cette classification offre un premier aperçu. Elle demeure à ce jour unique en Europe par son niveau de détail, mais atteint toutefois ses limites dès qu’il s’agit de formuler des constats par secteur économique ou même de définir les mesures à prendre. Pour une évaluation plus nuancée, il est nécessaire d’avoir recours à un regroupement (clustering) plus fin par activité économique, qui permet d’une part des analyses plus approfondies et, d’autre part, une planification et une mise en œuvre plus ciblées des mesures destinées à assurer la sécurité d’approvisionnement. Un tel clustering repose sur les profils de charge, c’est-à-dire les données issues des compteurs intelligents (smart meters). Pour réaliser ce clustering, les profils de charge fournis par les gestionnaires de réseau de distribution (GRD) doivent être associés à des informations sur l’entreprise. Les codes Noga, qui classent les entreprises en fonction de leur activité économique, jouent ici un rôle essentiel. La Noga signifie «Nomenclature générale des activités économiques» et désigne la systématique suisse de classification des branches économiques.
Une étude pilote menée avec l’OFEN a examiné dans quelle mesure les profils de charge fournis par les GRD pouvaient être reliés aux données de base et classés par activité économique à l’aide des codes Noga. Pour ce faire, deux approches ont été envisagées: d’une part, l’attribution des codes Noga via des données de base telles que le numéro d’identification des entreprises (IDE) et, d’autre part, via une classification assistée par IA sur la base des profils de consommation. Dans le cas de l'approche reposant sur les données de base, l'UID a permis d'attribuer pratiquement tous les profils de charge à un secteur économique (l'une des 99 divisions Noga). La classification assistée par IA n'a en revanche atteint qu'une précision de 85% pour l'attribution des profils de charge aux trois divisions Noga les plus courantes. Les résultats montrent clairement que pour une classification exhaustive des 99 divisions Noga, il faut disposer de données nettement plus nombreuses et plus variées.
Ceci pourrait également vous intéresser

